
Erfolgsgeschichten
Wir setzen die Bedürfnisse unserer Kunden an erste Stelle
Denn wir wissen, worauf es ankommt: Deine Probleme sorgfältig und dauerhaft zu lösen
Analytischer Cloud-Datalake für die Fertigung
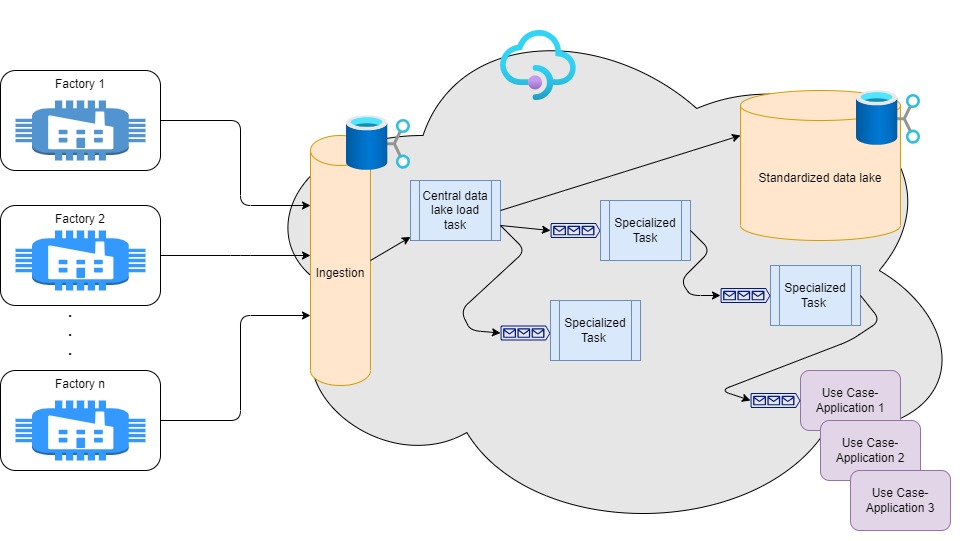
Ein bekanntes Fertigungsunternehmen sah sich mit der Herausforderung konfrontiert, Schrottteile schneller und mit weniger schwer zu schulendem Personal zu identifizieren. Wir setzten unser umfassendes Fachwissen in den Bereichen Cloud-Technologien und Microsoft Azure ein, um für den Kunden einen hochentwickelten Datalake aufzubauen, der große Mengen an Fertigungsdaten, insbesondere Bilder aus der Computer Vision, aufnehmen, speichern und in Echtzeit verarbeiten kann. Dies ermöglichte es den KI-Experten, Modelle mit standortübergreifenden Bilddaten zu trainieren und aus der Cloud zurück auf die Produktionsmaschinen zu deployen.
Durch die Nutzung von Technologien wie Infrastructure-as-Code und Cloud-Ressourcen wie Queues und Kubernetes (AKS) konnten wir einen schnellen, responsiven und dennoch kosteneffizienten spezialisierten Cloud-Datalake schaffen. Zudem wurde ein detailliertes Rollenkonzept entwickelt, das nahtlos in das Active Directory des Unternehmens integriert ist. Dieser Anwendungsfall veranschaulicht unsere Stärke, modernste Technologien einzusetzen, um reale Cloud-Herausforderungen zu lösen und den Geschäftswert von Unternehmen zu steigern.
Umfeld
Fertigung, Maschinenteile
Skills
Cloud Engineering, Massendatenverarbeitung,
Entwicklung von Echtzeitsystemen
Umfang
12-monatige Erstentwicklung mit regelmäßigen Erweiterungen
der Datenquelle
Technologien
Azure, Queues, Storage Accounts, Federated Identities, Python
Telemetry Backbone (TBB)
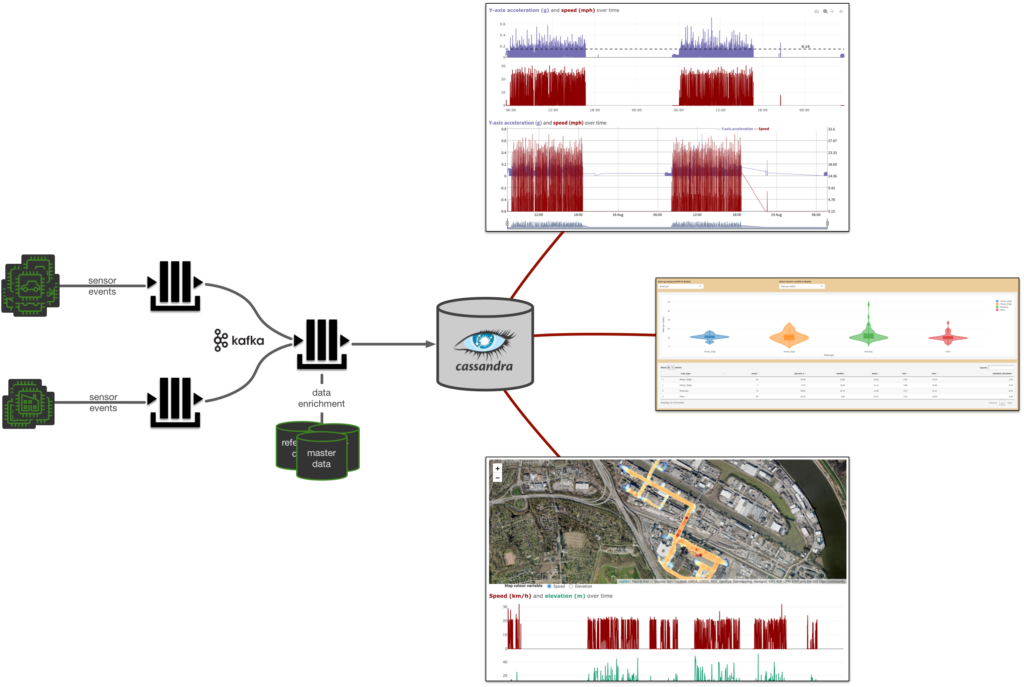
In der Automobilbranche steigt der Anteil digitaler Zusatzdienste an der Wertschöpfungskette rasant. Eine wesentliche Basis zur Erzeugung von digitalen Services sind Telemetrie-Daten von Fahrzeugen und Fahrzeugkomponenten. In einem Projekt für einen global tätigen Automobilzulieferer haben wir den Telemetry Backbone entwickelt, eine Daten-Streaming-Architektur, die aus Big-Data Fast-Data macht. Die Sensor-Daten werden in Echtzeit gestreamt und gespeichert und stehen unserem Kunden somit sofort zur Verfügung. Zudem agiert der Telemetry Backbone als Datenverarbeitungspipeline, in der die Rohdaten angereichert und mit Qualitätsindikatoren versehen werden können. Dies ermöglicht eine erhöhte Datenqualität und Informationstiefe, ohne die ursprüngliche Granularität zu verlieren.
Doch was bedeutet das konkret für unseren Kunden? Der Telemetry Backbone hat sich besonders in drei Bereichen als enormes Asset erwiesen: Data Scientists ermöglicht er die Implementierung von Machine Learning Modellen zur Vorhersage von Haltbarkeit und Wartungsintervallen des Reifens (Predictive Maintenance). Im Bereich Qualitätsmanagement lassen sich anhand der aufbereiteten Daten die Ursachen für einen frühzeitigen Qualitätsmangel nachvollziehen und auch für die Produkt- und Kostenoptimierung spielt der TBB eine wichtige Rolle: Hier können die Daten dazu genutzt werden, mittels KI zu simulieren, welche Auswirkungen Modifikationen in Hinblick auf Materialzusammensetzung und Verarbeitung hätten.
Umfeld
Produktion, Qualitätsmanagement, Predictive Maintenance
Skills
Cloud Scaling, Data Engineering,
Data Science, Infrastruktur
Umfang
Ein Jahr Entwicklungsdauer mit regelmäßigen Erweiterungen
Technologien
Java, Kafka, Cassandra, AWS, Kubernetes
AWS Identitätszugriffsverwaltung
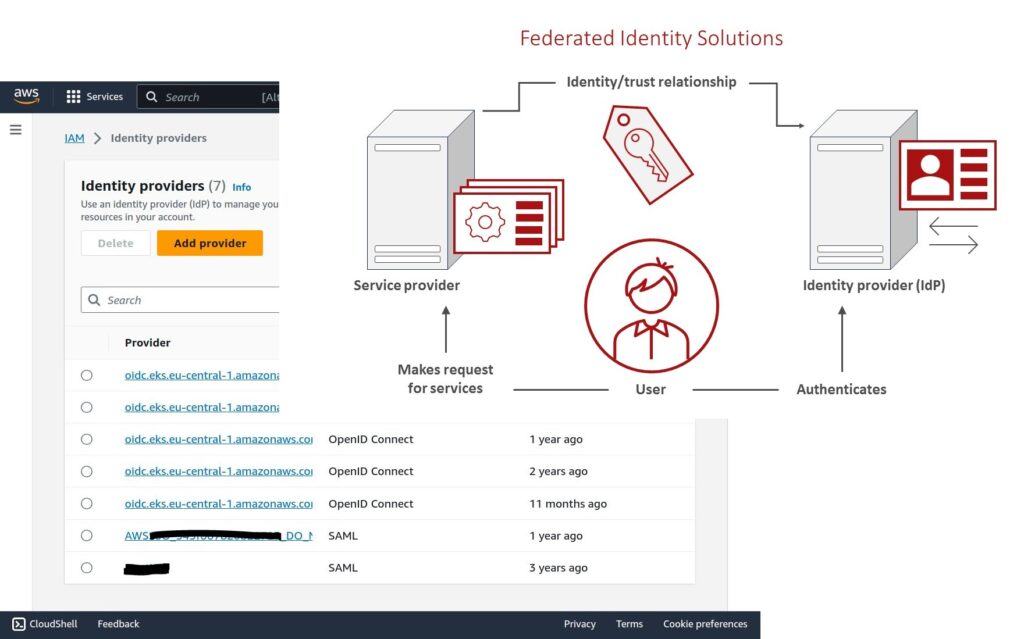
Ein großer Kunde aus der Fertigungsindustrie hatte Probleme mit der Sicherheits- und Konfigurationsverwaltung mehrerer Legacy-Cloud-Anwendungen. Wir berieten ihn bei der Bewältigung der Herausforderungen von Rollen und Berechtigungen, indem wir die Anwendung von temporären Credentials, anstelle von lokal verwalteten wie Schlüsseln / Geheimnissen, strikt durchsetzten. Darüber hinaus ermöglicht die Identity Federation unserem Kunden die Nutzung vorhandener Identiy-Provider wie Active Directory ohne die zusätzliche Belastung der Verwaltung dedizierter Benutzer und Credentials.
Um dies zu implementieren, erstellten wir eine schlüssige und kundenspezifische Checkliste und Dokumentation, hielten Workshops ab und schulten Administratoren. In der Cloud nutzten wir IAM-Rollen und Workload-Identities, um die Ausgabe und den Verbrauch von kurzlebigen sicheren Token zu standardisieren und automatisieren. Durch den Einsatz von Federated Identities in Kombination mit Cognito gelang uns eine nahtlose Integration des bestehenden Benutzerpools und dessen Rollen und Berechtigungen auf Cloud-Ressourcen.
Umfeld
Cloud-Infrastruktur und -Sicherheit
Skills
Federated Identity, IAM-Verwaltung
Umfang
3-monatige Einrichtung mit laufendem Support / administrativer Beratung
Technologien
AWS IAM, Roles, Permissions, Policies, Workload-Identities
Migration von GCP zu Azure
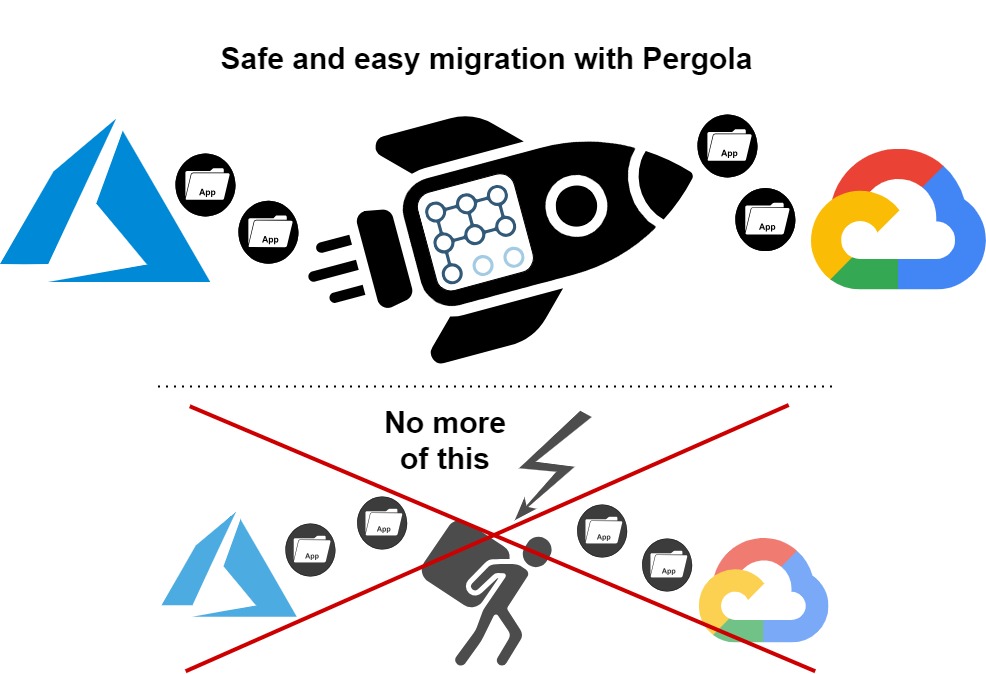
Ein Kunde aus der Lebensmittelindustrie hatte verschiedene containerisierte datengesteuerte Anwendungen entwickelt, die in Microsoft Azure liefen. Als das Unternehmen diese Anwendungen in eine private Google Cloud Platform-Umgebung migrieren wollte, um exklusive Funktionen wie Big Query zu nutzen, sah es sich mit Hindernissen konfrontiert. Hier kamen wir ins Spiel: In verschiedenen technischen Planungssitzungen erstellten wir für unseren Kunden sowohl einen vereinfachten Cloud-Infrastrukturplan auf Basis von Kubernetes und Pergola als auch einen detaillierten technischen Migrationsplan.
Unsere Entwickler richteten zunächst die neue CGP-Infrastruktur ein und testeten verschiedene Anwendungsfälle unter Nutzung des Staging-Konzepts von Pergola, bevor sie die produktiven Umgebungen migrierten. Dies reduzierte nicht nur die Herausforderungen von Datenmigration und Netzwerkzugriffsproblemen, sondern schulte die Anwendungseigentümer gleichzeitig in den anspruchsvolleren CICD- und Softwareentwicklungs-Lebenszyklusprozessen, die die neue Plattform ermöglicht.
Umfeld
Cloud-Infrastruktur, Lebensmittelindustrie
Skills
Cloud-Platform-Design,
Planung der Systemmigration
Umfang
2,5-monatige Einrichtung und Planung mit verschiedenen Einzelmigrationen über einen Zeitraum von 4 Monaten
Technologien
Kubernetes, Pergola, Azure Cloud
Marketplace Lense
Zusätzlich befeuert durch die Coronapandemie, ist der Umsatz im B2C-E-Commerce in Deutschland im Laufe der letzten Jahre rasant gestiegen. Wie in herkömmlichen Suchmaschinen, klicken potentielle Käufern auch bei ihrer Produktsuche nur auf die ersten Ergebnisse. Alle Angebote ab der zweiten Seite sind quasi unsichtbar. Deshalb sind Produktrankings ein entscheidender Erfolgsfaktor für Online-Retailer. Je höher das Ranking, desto höher der Verkauf. Einer unserer großen Marketingkunden hilft Unternehmen dabei, die Sichtbarkeit ihrer Produkte auf E-Commerce-Plattformen zu optimieren. Ohne die entsprechenden Daten ist das jedoch nicht möglich, was uns ins Spiel bringt: Wir kümmern uns um die detaillierte Erfassung und Visualisierung der Produktrankings als bestmögliche Grundlage für erfolgreiche Marketingstrategien.
Wir analysieren mehrmals täglich vordefinierte Produkt-Keyword-Sets auf den lokal und global umsatzstärksten E-Commerce-Plattformen. Ausgewertet und visuell aufbereitet stellen wir unserem Kunden und seinen Klienten die KPIs in einem personalisierten Dashboard mit individuellem User-Management zur Verfügung. Mit Reports zum Share of Voice des Klienten, seiner Sichtbarkeit im Vergleich zu wichtigen Wettbewerbern oder seiner tageszeit- und wochentagsabhängigen Performance geben wir Trends für ganze Unternehmen oder einzelne Produkte an – Trends mit enormem Benefit für Online-Retailer jeder Größe.
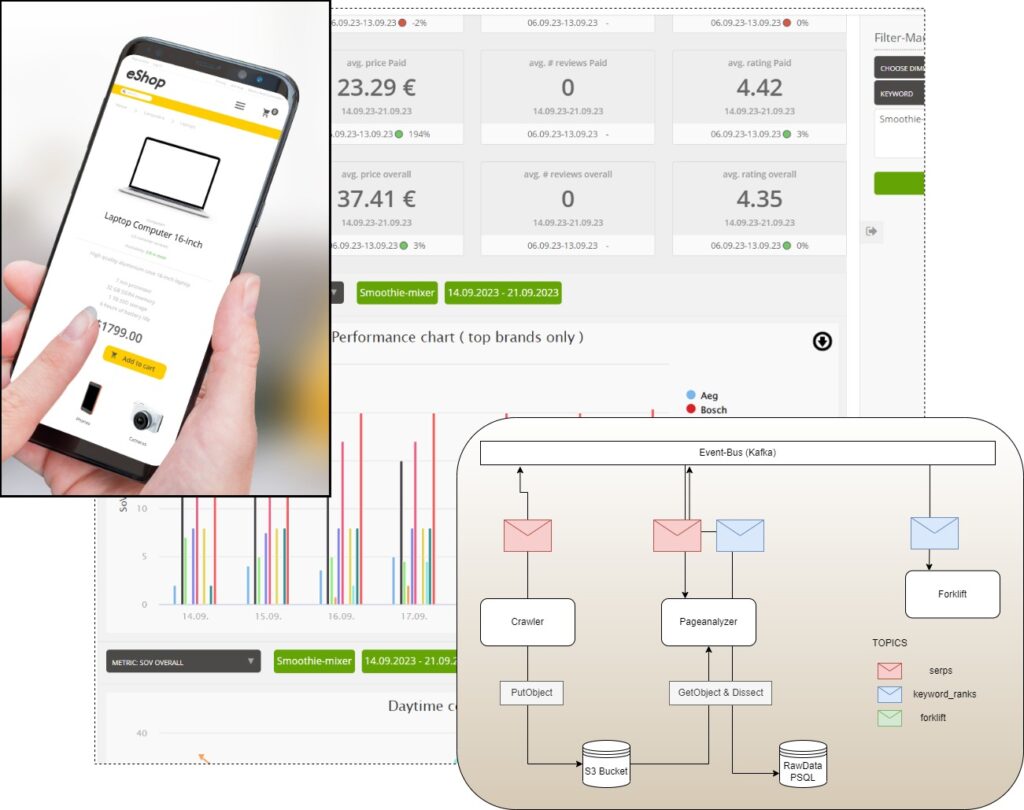
Umfeld
Online-Retailer, Marketing- und
SEO-Experten
Skills
Softwareentwicklung, Webdesign,
Back- und Frontend, Cloud-Infrastruktur
Umfang
Ein Jahr Entwicklungsdauer mit regelmäßigen Erweiterungen
Technologien
Python, Java, Javascript, Terraform
Online/Offline Sales BI und Reporting
Angesichts der Zunahme von Online-Marketing und -Handel im Vergleich zum traditionellen Agenturvertrieb musste eine global tätige Versicherungsgesellschaft ihren internen Business-Intelligence-Prozess aktualisieren, um beiden Kanälen bestmöglich Rechnung tragen zu können.
Gemeinsam mit dem Kunden erarbeiteten wir eine Reihe technisch umsetzbarer Anforderungen, die es uns ermöglichten, alle Online- und Offline-Daten in einem einzigen Datensatz zusammenzuführen und sogar eine Online-Attribution zu Offline-Verkäufen für eine Reihe von KPIs abzuleiten, welche die Wirksamkeit von Marketingkampagnen auf traditionelle Offline-Verkäufe messen.
Zur Verarbeitung von Daten aus bereits bestehenden Datenbanken sowie Massendaten aus der Online-Verfolgung wandten wir unsere internen Open-Source-basierten Data-Warehouse-Ansätze an. Anstelle der Nutzung von Cloud-Ressourcen, limitierten uns gesetzliche Bestimmungen hierbei auf eine Vor-Ort-Infrastruktur. Es gelang uns, skalierbare, auf virtuellen Maschinen basierende Setups auf vorhandener lokaler Hardware einzusetzen, um sowohl die Saisonabhängigkeit der Kampagnen als auch die zunehmende Menge der verfolgten Online-Interaktionen zu bewältigen. Die hieraus resultierenden Management-Board-Reports stellten wir unserem Kunden über browserbasiertes Reporting und E-Mail-Reporting bereit.
Umfeld
Sales, Versicherungen
Skills
Data Engineering, Domainanalyse, Massendatenverarbeitung
Scope
6-monatige Erstentwicklung mit regelmäßigen Erweiterungen
der Datenquelle
Technologien
Java, PostgresSQL, Ansible, Javascript
MLOps: Organisiere Deine Machine Learning Modelle besser
Jeder, der mit Modellen an vielen Daten trainiert und optimiert, kennt das Problem: Einen guten Überblick über die verschiedenen Modelle, Datensätze und Parameterkonfigurationen zu behalten, kann echt nervig sein. Es dauert mindestens genauso lange, eine halbwegs vernünftige Übersicht zu programmieren, wie die Modelle selbst. Welche Parameter habe ich nochmal benutzt? Welches Modell kann ich verwerfen? Wir halfen einem Kunden aus der Automobilbranche, eine systematische Lösung für diese Fragen zu entwickeln. Aufbauend auf einer Vielzahl an Open-Source-Software, fanden wir eine einfache Möglichkeit, Machine Learning Metadaten zu tracken, was den Experten wiederum mehr Zeit für die Weiterentwicklung der Algorithmen und Modelle gibt.
Mit plotly Dash haben wir ein Dashboard gebaut, um Datensätze und Modellparameter zu spezifizieren. Das Dashboard ermöglicht dem Nutzer Kubernetes Jobs zu starten, um Modelle zu trainieren und Vorhersagen zu treffen. Mittels dem Load Balancing können mehrere Jobs parallel laufen, in ihren eigenen unabhängigen Docker Containern und der gewünschten Hard- und Softwarespezifikation. Modellparameter, Metadaten und Vorhersagen werden in einer Postgres Datenbank gespeichert, Modelle, Scaler und Checkpoints für spätere Wiedernutzung und für das Tensorboard im S3 Bucket. Im Tensorboard kann Modellperfomanz evaluiert werden. Die einzige Aufgabe, die dem Entwickler bleibt, ist die Modellentwicklung in Python und Codepersisiterung in eine git Repository.
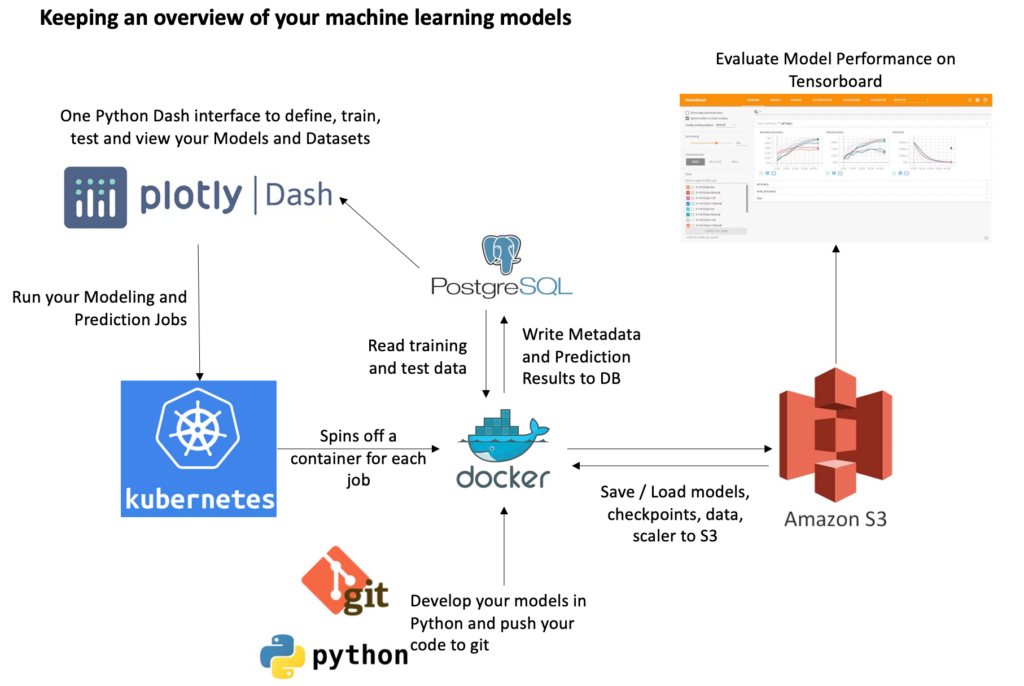
Umfeld
Data Scientists, Data Engineers
Skills
Cloud-Infrastruktur, Softwareentwicklung
Umfang
Die Softwaresuite wurde prototypisch in zwei Monaten gebaut
Technologien
Kubernetes, Docker, Python 3, Dash, PostgresSQL, AWS, Tensorboard
AWS Cloud-Image-Intake
Ein führendes Industrieunternehmen hatte Schwierigkeiten, von Kunden aufgenommene Produktbilder in die private AWS-Cloud des Unternehmens zu übertragen. Mit unserer Expertise im Bereich Amazon Web Services (AWS) bauten wir eine sichere Cloud-Infrastruktur auf, die alle Bilder annehmen und speichern kann und gleichzeitig strenge Sicherheitsprotokolle nach außen hin aufrechterhält.
Der Anwendungsfall war sowohl breit gefächert – jedes Bild kann jederzeit von jedem Ort aus hochgeladen werden – als auch kleinteilig – nur ein paar Hundert Uploads pro Tag. Wir bauten auf AWS Managed Services wie API Gateway, Lambda Serverless usw., um eine global verfügbare und kosteneffiziente Lösung bereitzustellen, die in der Zukunft bei Bedarf skaliert werden kann.
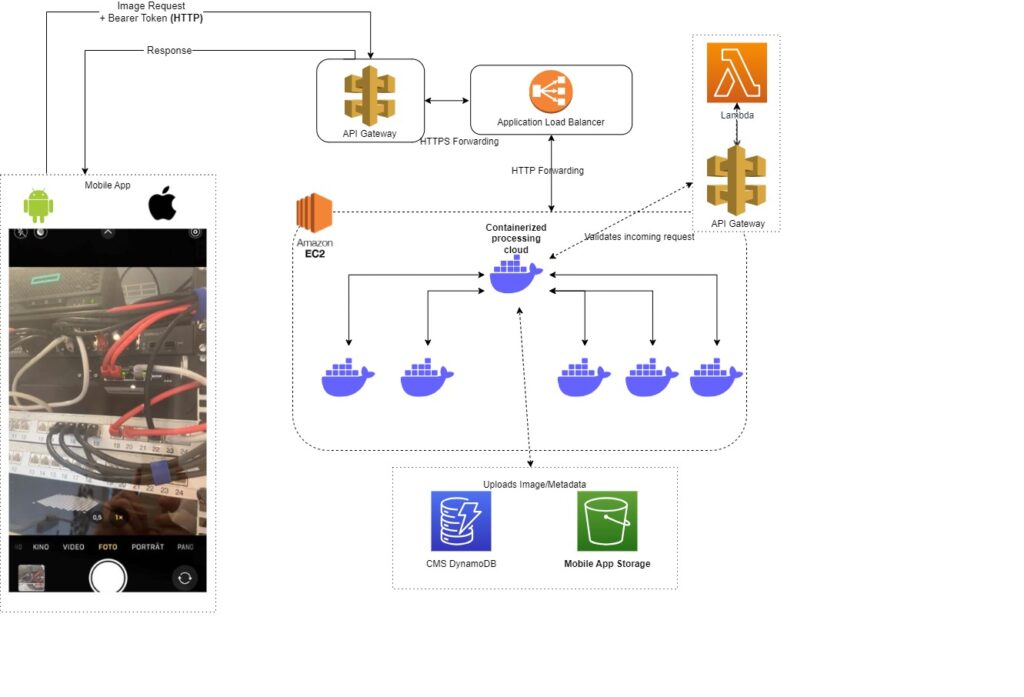
Umfeld
Predictive Maintenance, Automobilindustrie
Skills
Netzsicherheit,
Cloud Service Design, FinOps
Umfang
4-monatige Entwicklungsdauer
Technologien
Python, AWS Managed Services
Search Engine Optimization mit Keyword Clustering
Einer unserer großen Marketingkunden ist im Bereich Search Engine Optimization (SEO) für tausende Webpages aktiv. SEO bedarf einer gehörigen Portion Analyse Know-How, um die Webseiten so zu bauen, dass sie bei Google-Suchen ganz oben auf der Ergebnisliste stehen (mehr Traffic und Clicks). Wir haben eine interaktive App gebaut, um Suchbegriffe semantisch (Natural Language Processing) und netzwerkanalytisch zu clustern. Mit diesen Analyseergebnissen kann unser Kunde die Webseiten viel einfacher erstellen und sichergehen, dass sie höher ranken als Seiten der Wettbewerber.
Unser Kunde stellt uns eine Liste mit tausenden Suchbegriffen zur Verfügung, für die wir Google-Suchanfragen abrufen (web scraping). Sobald die Daten geladen sind, erkennt unser Algorithmus anhand von Netzwerk- und semantisch-lexikaler Analyse, wie Suchbegriffe miteinander verknüpft sind. Wir ermitteln die best-vernetzten und zentralsten Suchbegriffe, die größten Cluster und Beziehungen zwischen verschiedenen Suchbegriff-Clustern oder Themen. Die Ergebnisse können in einem interaktiven R Shiny Dashboard angezeigt und in Excel heruntergeladen werden.
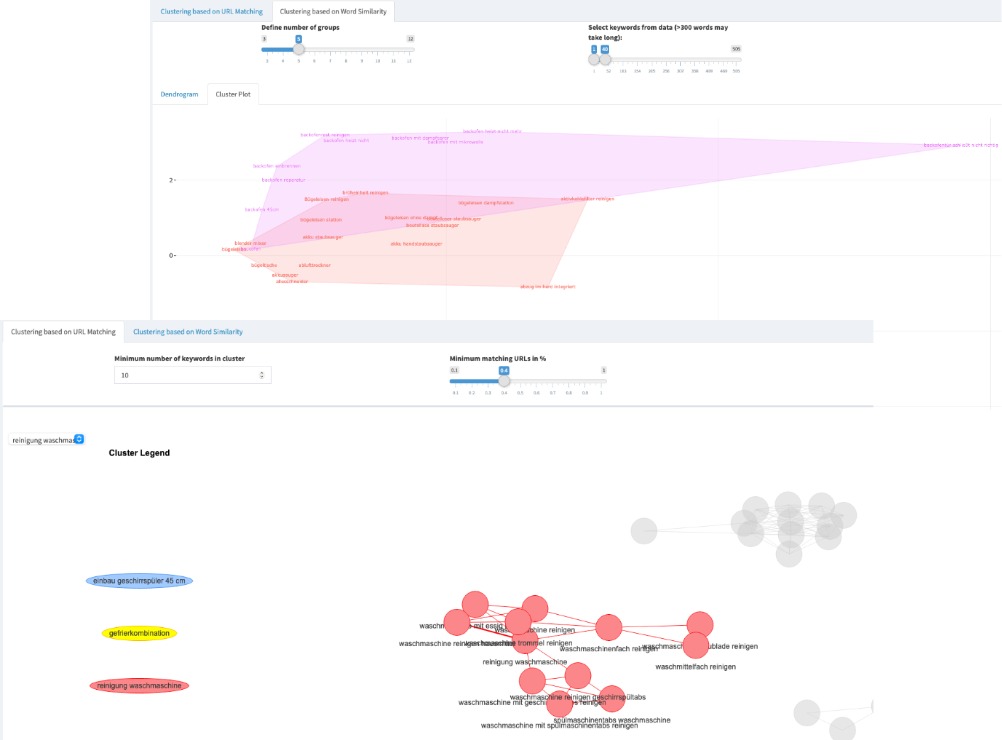
Umfeld
SEO- und Marketingexperten
Skills
Webdashboard für Visualisierung und Datendownload in Excel
Umfang
Ein Jahr Entwicklungsdauer mit mehreren Iterationsrunden
Technologien
Netzwerkanalyse, Natural Language Processing, R Shiny, Web Scraping